Fighting Frenzy
AI-generated card game

2022
Machine Learning Experiment
Python / GPT3 / Stable Diffusion
Solo
Fighting Frenzy was an exploratory project I built over the course of a weekend in late 2022 to explore the potential uses of machine learning and AI in game design. The basic premise was to see how much of a game's overall design could be produced by an LLM (Large Language Model), keeping human involvement as minimal as possible outside of infrastructure and implementation.
The project used GPT-3 for game design and mechanics and Stable Diffusion for card art. Additionally, I used this project as an opportunity to explore some data analysis and visualization techniques, as well as to brush up on my python.
Everything in Fighting Frenzy is AI-generated, including the game's core ruleset.
The process of generating this ruleset mainly consisted of an interactive prompting-and-playtesting loop that roughly adhered to the following pattern:
The process of generating this ruleset mainly consisted of an interactive prompting-and-playtesting loop that roughly adhered to the following pattern:
- Prompt GPT-3 to generate an initial ruleset.
- Generate several hundred cards with the specified ruleset.
- Play a few matches with a friend using the cards generated, noting down feedback as we play.
- Prompt GPT-3 to modify the previously generated ruleset to account for problems identified in playtesting.
- Repeat steps 2-4 until a satisfactory ruleset is achieved.

Card-generation was achieved via a command-line python tool I built. The primary method of producing new cards involved prompting GPT-3 with the following information:
- a copy of the ruleset
- a specification of the card format so that results would be machine-parseable
- a brief description of the kind of cards to generate (eg "Generate cards from the Goblin set, which focus on Poison and Traps").
Additionally, the tool exposed functionality for several other features:
- Manual modification of cards
- AI-based modification of cards, in which the user could ask for specific cards to be reworked or improved
- Various visualizations and analytics performed across the database generated cards
- Tools for ranking and comparing cards by uniqueness or power
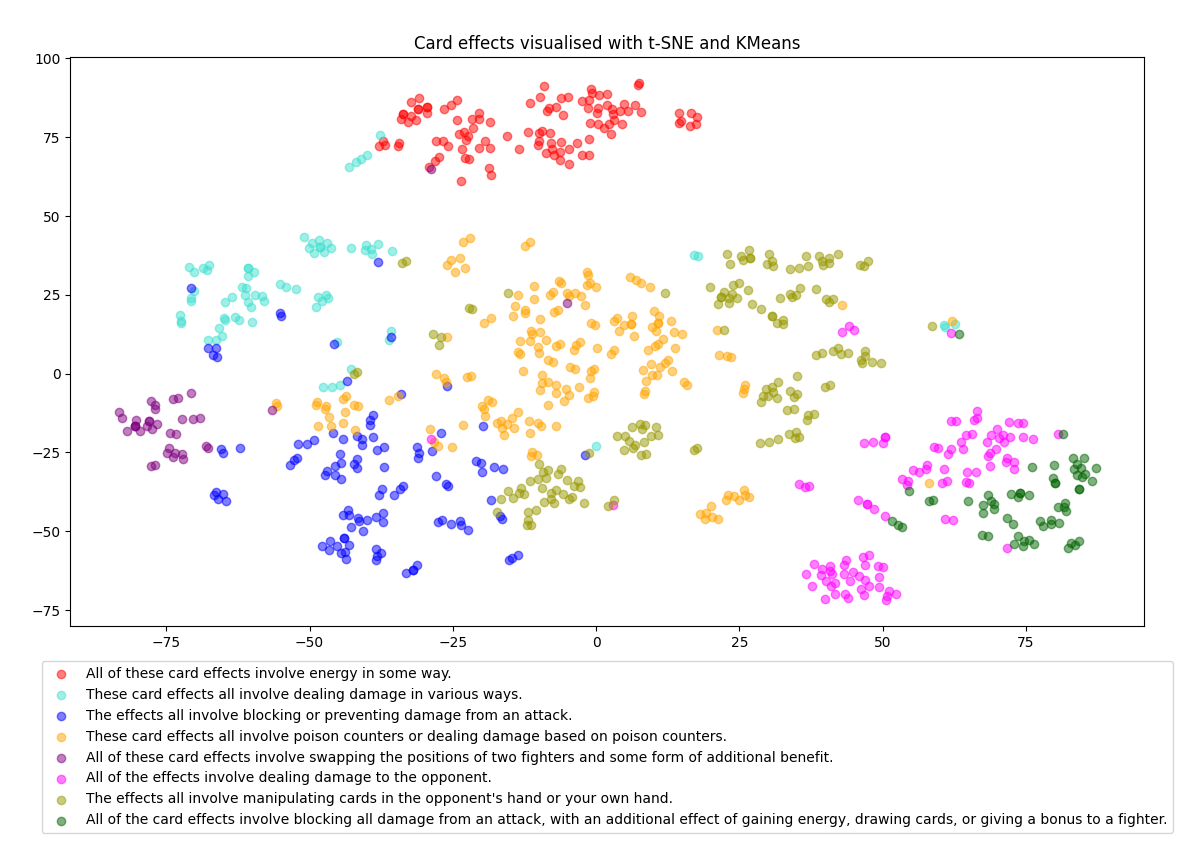
In order to more easily evaluate the relatively large number of cards I was generating, I implemented a toolkit for AI-assisted data visualization. This would also double as an opportunity to use a python library I had been looking at called scikit-learn, which included both machine learning and data visualization tools.
The primary visualization I relied on (shown above) was generated via the following process:
- For every card, I produce an embedding using GPT-3. These embeddings are high-dimensional vectors that correspond to the card's representation in the first layer of the neural network.
- I then reduce these vectors to a 2-dimensional space using a dimensionality reduction technique known as t-distributed stochastic neighbor embedding, or t-SNE, which produces a human-readable representation of the similarity between cards.
- Additionally, we group the embeddings into several clusters of similar cards using an algorithm called K-Means. This produces the colored segments shown above, representing groups of semantically similar card effects.
- Finally, I produce an analysis of each identified cluster by feeding a set of example card effects from that cluster back into GPT-3, along with a prompt to identify the similarities between them.
- All of this data is then presented in the above visualization, which also includes interactive functionality for inspecting individual cards.
 Due to the limited input bandwidth (called "context") available to a GPT-3 prompt, it wasn't possible for cards to be generated in a way that was aware of all existing pre-generated cards. Because of this, very similar cards tended to be generated repeatedly across different batches, especially when asking for a specific theme or keyword. For example, when asked for poison cards, almost any batch would contain a couple baseline "deal damage and apply poison" cards.
Due to the limited input bandwidth (called "context") available to a GPT-3 prompt, it wasn't possible for cards to be generated in a way that was aware of all existing pre-generated cards. Because of this, very similar cards tended to be generated repeatedly across different batches, especially when asking for a specific theme or keyword. For example, when asked for poison cards, almost any batch would contain a couple baseline "deal damage and apply poison" cards.
In order to facilitate a more interesting and diverse set of card effects, I built an automated pipeline to cull these similar cards and replace them with new, more unique cards. This system utilized a GPT-3 endpoint that generates an embedding from a given text string -- a numerical representation of the neural network's understanding of the concept represented by that text.
By computing embeddings for all of our generated cards and then comparing them via various distance functions, we're able to get a rough idea of which cards are similar to which other cards. We can then automate a process that eliminates cards that are too close together in the embedded space, condensing clusters of very similar cards into a single representative card. Additionally, if we wish to maintain the overall distribution of card effects, we can ask GPT-3 to re-generate thematically similar but mechanically distinct versions of the removed cards, and repeat the process until satisfied with the overall variety and distribution of cards.
Fighting Frenzy provided a few particularly compelling opportunities to explore a machine learning technique known as Amplification, which allows us to turn a bad or inefficient decision process into a more effective one by repeating the process.
The initial problem that prompted this exploration was GPT-3's difficulty adhering strictly to the JSON spec I expected cards to be generated in. Results correctly adhered to the format for about 90% of generated cards. Because cards were generated in large batches, a 10% fail rate per card resulted in a large frequency of unparsable batches.
In order to fix this problem, I passed any set of cards that failed to parse back to the GPT-3, this time asking it to correct formatting errors in the JSON. With an ~80% success rate on identifying these errors, our overall success rate improved from about 90% to about 98%. It's worth noting that this process wasn't indefinitely repeatable - If GPT was unable to identify an error in its first correction pass, it was very unlikely to identify that same error if asked again.
A similar process could be performed within the domain of card design - by asking GPT to generate several variants of a card, discarding the less interesting or unique results, and then repeating the process, I was able to automate a system that resulted in overall more compelling cards without any additional human input.
The initial problem that prompted this exploration was GPT-3's difficulty adhering strictly to the JSON spec I expected cards to be generated in. Results correctly adhered to the format for about 90% of generated cards. Because cards were generated in large batches, a 10% fail rate per card resulted in a large frequency of unparsable batches.
In order to fix this problem, I passed any set of cards that failed to parse back to the GPT-3, this time asking it to correct formatting errors in the JSON. With an ~80% success rate on identifying these errors, our overall success rate improved from about 90% to about 98%. It's worth noting that this process wasn't indefinitely repeatable - If GPT was unable to identify an error in its first correction pass, it was very unlikely to identify that same error if asked again.
A similar process could be performed within the domain of card design - by asking GPT to generate several variants of a card, discarding the less interesting or unique results, and then repeating the process, I was able to automate a system that resulted in overall more compelling cards without any additional human input.
Card art was generated by Stable Diffusion, using a model I fine-tuned to produce results in a relatively consistent style appropriate for card art. Text prompts for image generation were generated by GPT-3 and modified via a special set of weights and parameters manually tuned for this specific use case.